

 Bienvenido a este tutorial sobre UBot y web scraping.
Bienvenido a este tutorial sobre UBot y web scraping.
Voy a considerar que no conoces esta herramienta y haré una breve introducción al uso del editor.
Para insertar comandos o atributos en UBot pulsaremos CTRL+E y escribiremos en el cuadro de búsqueda o Search Toolbox.
De esta forma trabajaremos más rápido que buscando cada una de las opciones desde el panel, y más si tenemos en cuenta que cuando tengamos instalados algunos plugins es prácticamente imposible tener cierta agilidad a la hora de programar.
Vamos a usar $scrape atribute y pulsaremos el botón <>. Esta opción nos permite movernos sobre el navegador y seleccionar un elemento de forma interactiva.
Ubot intentará seleccionar el elemento sobre el que pulsemos con un identificador único.
Por ejemplo, si queremos extraer el título de un producto de Amazon, haremos clic y en este caso Ubot tomará como identificador <id=”productTitle”>.
Podemos utilizar también el editor avanzado pulsando sobre el pequeño engranaje morado, que nos permite visualizar el DOM y configurar el atributo que deseamos seleccionar entre otras opciones.
En principio solo encontraremos un elemento con el mismo id en cada página.
En este ejemplo, productTitle es el identificador que contendrá el título del producto y como es de esperar, no hay otros elementos que estén marcados con ese mismo id.
Para verificar esto miraremos en la ventana del editor avanzado, donde se nos muestra que el número de Matches es igual a 1.

Si seleccionamos una clase (class) en lugar de un identificador es muy probable que tengamos varios elementos utilizándola.

UBot intentará siempre devolverte algo único respecto al elemento que has seleccionado.
Vamos a escribir innertext y ejecutamos el código para ver que nos muestra el depurador (CTRL+D).

Si nunca has utilizado UBot, lo que está sucediendo es que estamos almacenando el valor que hemos extraído de la web y lo almacenamos en una variable, llamada #tituloProducto.
Para visualizarla usaremos el comando alert.

Esta es la forma simple de escrapear contenido usando una variable.
Podría darse el caso de que necesitásemos extraer una lista de elementos.
Veamos como se hace.
Uso de listas en Ubot
Voy a aclarar un concepto muy importante y que evitará que cometas errores: en general, siempre limpiaremos o vaciaremos una lista antes de usarla.
UBot no inicializa las variables en cada ejecución por lo que los contenidos en la memoria pueden contener datos de ejecuciones previas y es algo que en general no nos va a interesar.
Siempre es una buena idea limpiar cualquier lista que vayamos a utilizar al comienzo del script.
En ciertos casos quizá también tengamos que borrarla en otro punto del programa como por ejemplo antes de un bucle.
Vamos a ver un ejemplo.
Queremos extraer los precios de todas las variaciones de este producto.
En esta ficha de artículo, tenemos un Kindle y está la versión en blanco y la versión en negro, y podría darse el caso de que su precio fuera diferente según el color.
Si le damos un vistazo al código html encontramos algo similar a esto:
<span class="a-size-mini twisterSwatchPrice"> EUR 79,99 </span>
Ya hemos visto que aunque los identificadores suelen ser únicos, las clases suelen reutilizarse.
Si extraemos el valor de la clase tal podremos extraer los precios, tal como vemos en la siguiente imagen.
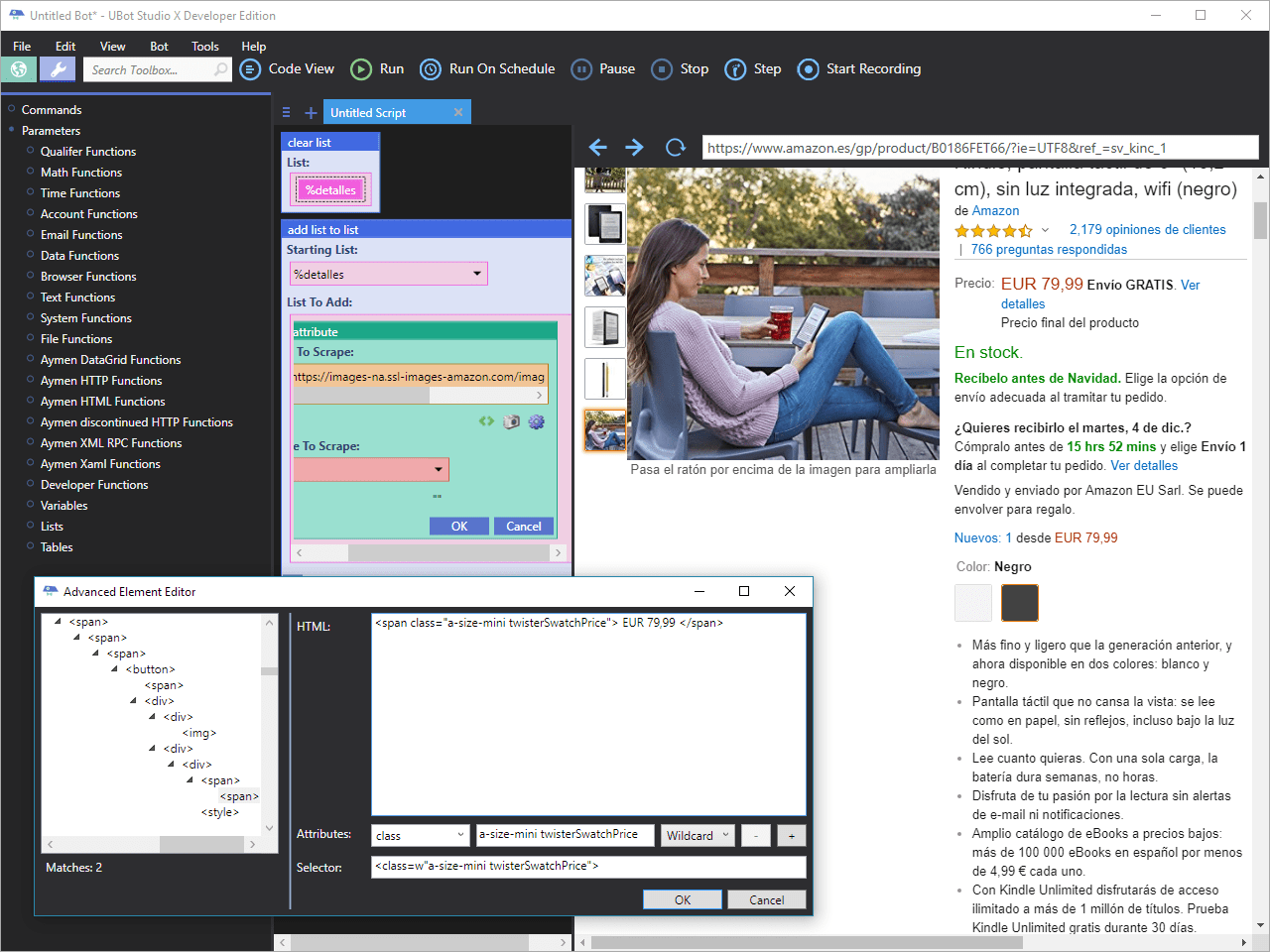
Tal y como he comentado más arriba, si no limpiamos la lista y volviésemos a ejecutar el script, los datos se volverían a añadir en la lista junto a los que había en la ejecución anterior.
Hago un inciso para aclarar que en este caso he marcado la opción “Don’t delete duplicates” para que obtenga los precios, aunque en este caso sean iguales.

Estas son las dos cosas fundamentales que tendremos que vigilar en UBot a la hora de escrapear: el reseteo de las listas y el control de duplicados.
Otro detalle que hemos pasado por alto es el valor que seleccionamos en Attribute To Scrape.
Tenemos: value, name, innertext, id, src, href… y muchos más para elegir.
Una vez hemos identificado el elemento en la página, con este atributo le indicaremos a UBot qué queremos seleccionar.
Por ejemplo, si queremos extraer el enlace del vendedor:
<a id="bylineInfo" class="a-link-normal" href="/Amazon/b/ref=bl_dp_s_web_8819629031?ie=UTF8&node=8819629031&field-lbr_brands_browse-bin=Amazon">Amazon</a>

Accederemos de la siguiente forma:

En general, una de las opciones que más usaremos a la hora de hacer scraping es innertext. Este atributo selecciona el texto que se visualiza en el navegador, limpiando también cualquier etiqueta html que encuentre.
Otra opción frecuente es elegir innerhtml, que respetará las etiquetas html interiores al elemento.
En $scrape attibute podemos escribir el atributo que necesitemos seleccionar sin mayor problema, no estamos limitados a los que despliega UBot.
Espero que esta pequeña presentación te ayude a entender como funciona el comando scrape y te sirva como introducción al uso de listas.