

Introduction to RTILA automation
Browser automation is the process of emulating human actions on a website, of course, without human intervention.
RTILA provides a simple but powerful language for automating scraping tasks.
You will be able to fill forms, handle with paginations, change selectors, action checkboxes, add delays or pressing buttons.
RTILA has around 50 commands to create your automation process.
There are 2 big groups, divided into ACTIONS and EVENTS.
ACTIONS are automation that not require interaction with the elements or the site, they can be a pause, show a notification, clear the cookies or rotate a proxy.
EVENTS are automation commands that require a target to work with, for example, click a button, populate a text field, focus an element, click on it, and so on.
With RTILA you will have an integrated visual editor that allows you to create loops, conditions, use variables and many other advanced features.
The automation commands are like small tasks and very easy to use, but let’s face it… with great power comes great responsibility.
You’ll have to fill those small pieces properly to work your target website.
For example, after creating a Click an element event, you will have to choose which one(s) RTILA has to click.
If you never used an RPA/macro tool before, I recommend you check the following video.
After clicking on INSPECT, you will be able to access the automation panel, located on the right of the screen.

Click the Add New button and choose the desired command.

Actions
Actions are commands that don’t require you to define a CSS selector.
That means actions are independent commands that do not require a page element to work with.

ALERT MESSAGE
An alert box is often used if you want to make sure information comes through to the user.
Set your desired string on the Message box.
You can write several lines without using end-line modifiers, just press RETURN to create a new line.
CLEAR COOKIES
When you are scraping, the browser saves some information from websites in its cache and cookies. The cache remembers parts of pages, like images, to help them open faster during your next visit. Cookies are files created by sites you visit.
Clearing the cookies will help you to start with a fresh instance of the browser, and for example, if you were signed in, you’ll need to sign in again.
EXTRACT RESULTS
This is a very important action that allows you to trigger RTILA’s parser on demand.
Don’t forget to add this action or you will get nothing.
Probably you will use it in almost all your scripts.
When your script does not use any automation command, this action is not required.
GO TO URL
By default, RTILA will navigate on every URL set in the URLs to crawl property set on URLs panel.
When nothing is set there, it will navigate to the URL to inspect defined on the project.

Those will be the starting base URLs.
You can define a navigation action (go-to-url):

And RTILA will navigate there.
If you don’t have URLs to crawl defined in your project, it will navigate from the URL to inspect to the new URL defined in the Action.
From the images above, it will load the gooogle.es page and go to scraper.es/action page, just one jump.
If you define some URLs to crawl, the gooogle.es page will be discarded as we said before:

And now RTILA will generate this navigation:
scraper.es/1 → scraper.es/action → scraper.es/2 → scraper.es/action → scraper.es/3 → scraper.es/action
If some URL from the URLs to crawl is not found the automation/scraping will not be executed for that page.
GO FORWARD TO NEXT PAGE
Within the Chrome browser, you can navigate backward as well as forward on your history navigation.
This action will allow you to go forward.
Just as simple as that.
GO BACK TO PREVIOUS PAGE
As you can imagine, this is the real deal.
Sometimes you have to click on some link, scrape, and BACK TO PREVIOUS PAGE to continue.
Or maybe you need to send a form, scrape, and back to the form again.
You can use this action to emulate the back to the previous page button.
This is a very useful command to easily navigate on complex sites.
CLOSE PAGE
Some links could open a page on a new tab.
RTILA can force that kind of opening too (check the Target option from the Click on an element event).
Of course, you can set a scrape on tabs too and close them after that task is done.
This action will help you to close those unneeded tabs.
EXECUTE JAVASCRIPT CODE
Probably somebody could write a book here.

Just execute any javascript code with this action.
No limits.
MOCK LOCATION
When you launch RTILA, the browser automatically employ geolocation services that can pinpoint where you’re located. This is used for various purposes, including enabling you to use map services, tagging social media posts with your location, and serving targeted ads based on where you are at a given time. However, there are plenty of situations in which you’d prefer to hide your location and even change it (spoof).
RTILA allows you to define a particular location, setting the Country or the latitude and longitude coordinates.
You can use RTILA under a VPN or install some Chrome extension to be able to navigate on geo-restricted sites.
RELOAD PAGE
This is used to reload the current page.
The command will try to pull the document from the webserver again.
It’s the same action that does the refresh button.
SWITCH BROWSER IDENTITY
This action will allow you to switch between desktop, tablet or mobile.
Also, you can configure the desired screen resolution manually.
SOLVE RECAPTCHA
You can use a 2Captcha recognition service to solve Captchas without learning the internals.
Just don’t forget to set your API key on the project settings before using this action.

Navigating a site with Captchas is SLOW and can be expensive.
Solving 1000 Captchas can cost around 3$.
TAKE SCREENSHOT
This action will capture a full screenshot of the page you are browsing.
Before that, I recommend you to set the desired browser’s width from the Switch Browser Identity action.
Just set the download base path and the required jpg quality.
The resulting filenames will contain the last path of the page URL.
Some not allowed characters could be skipped on the filename.
If you only need to capture screenshots you can avoid using the Extract Results action.
WAIT NAVIGATION
This action will help you wait properly until the data is fully loaded.
There are several scenarios, if you are not a geek you can go with trial and error, the first ones are quick waits and the last ones are slow waits.
After HTML parsing
- When the dom is loaded and parsed, without waiting for images.
After page loading
- When the page is fully loaded and downloaded.
Single-page application
- Waits until no connections are done recently (zero connections).
Page that does long-polling
- Waits for at least 2 connections have not been made recently, great for ajax responses.
Check this project, as you see, we are more time waiting than working (click to enlarge).

WAIT TIME
Waits a random time between Min and Max Wait Time.
Please, consider adding a Wait Time or a Wait Navigation after every Click Event (or just after every situation that causes a request to the server).
Events
Events are commands that need to work with an element of the page.
They could interact with an HTML component too.

CLICK ON AN ELEMENT
This action will send a left mouse click event to your selected element.

You can use this action to click on buttons, links, or any other clickable element.
The CSS selector is mandatory.
You should check how many elements are you targeting (it’s the number on brackets).
The Element count option can be set to Single or Multiple.
Multiple option will create a list of elements and iterate (click) all of them in sequence.
For example, if you want to click on every listing, you will send a click to the elements link and set the Element count to Multiple.
After this probably you will add a Wait navigation or Wait time event, and then you can set an Extract results action.
Let’s see an example of this common structure, and please continue reading before implement this.

The first event is named Click on titles. I’m targeting the link headers of some e-commerce (you have to set your own selector).
I set the Element count to multiple, for this case let’s imagine we don’t have pagination on this particular site.
For the Target option, I forced to New tab. That means, when RTILA clicks on some link (in this case, on a product), it will be opened in a new tab.
After this, it will wait for the page is loaded, it will scrape the data, and … because we opened a New tab, we should close it!
That means, on the image above, we should keep the Option 2, and remove the Option 1 (Go back).
Just in case you decide to open the product on the same tab, usually the Default option, you should change the Close tab with a go-back-to-previous-page action.
Then, you have 2 nice options, scrape the detail pages on their own tab (closing them once we are finished with them) or just go and back from the parent to the listings, emulating some human navigation.
Please, note that you don’t have to add Option 1 and 2 at the same time. Just choose the proper one depending on how the Target setting was set or depending on how the site is opening the links.
When the site is opening the detail pages on new tabs by default, you can force this behavior from the Target option too.
REMEMBER to set a proper WAIT after a click. This will solve many of your timing issues.
CHECK RADIO INPUT
You can select a radio button with this event.

FOCUS AN ELEMENT
This event will set the focus on a particular element.
Sometimes you may have to focus on an element before it does accept keystrokes.
HOVER MOUSE OVER ELEMENT
In certain circumstances, you may need to hover the mouse over an element.
For example, you can hover an element to open a menu.
On the image below, I target the TAGS menu, hovering the mouse over it.
The menu reacts opening a dropdown.
Please, you have to differentiate FOCUS and HOVER, they are not the same thing. Hover is true when the mouse pointer is over an element. Focus is true if the cursor is in that element.

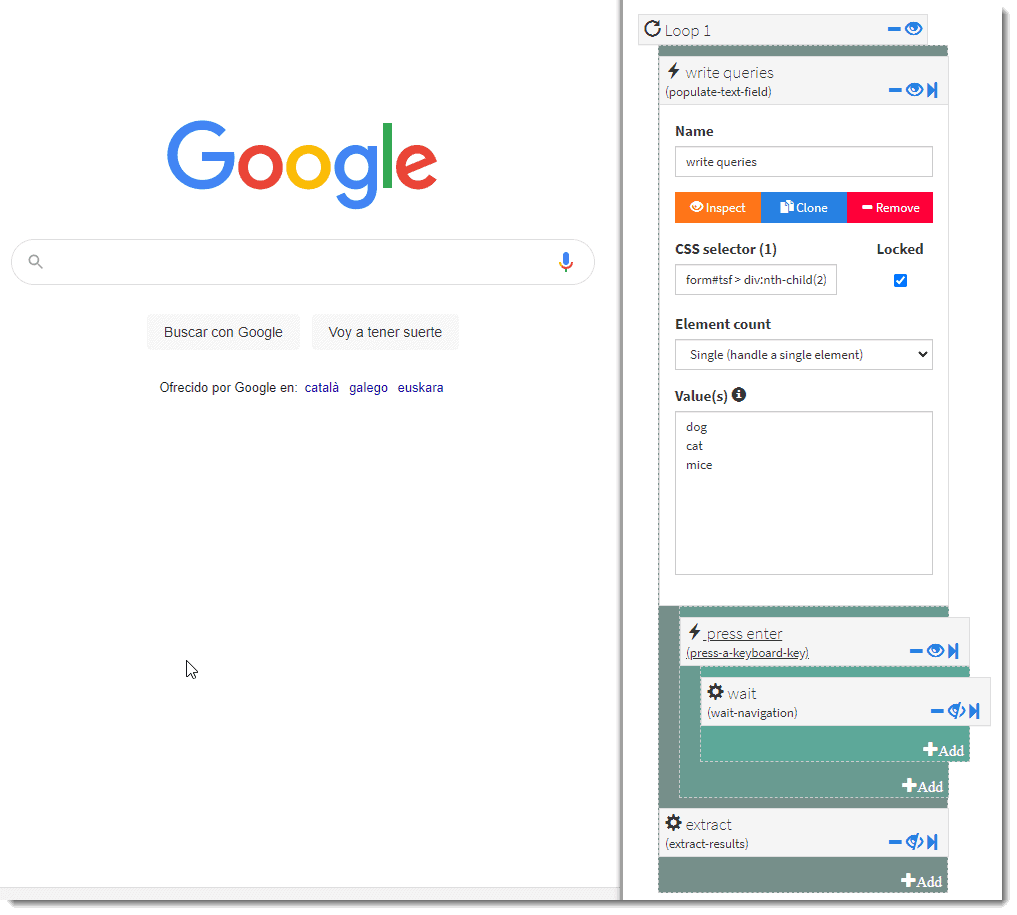
POPULATE TEXT FIELD
Probably on some occasions, you will need to send a text string to a website.
This is a very common scenario. Just set a populate-text-field action, set the selector to pointing where the text should be sent, and write the value(s).
In many cases, you will have to press enter or click some button. Remember to wait after those actions.
INFINITE SCROLLING
You can scroll the main site or some specific component.
Probably the most common sites that you have to scroll down are those that need to load more content dynamically (lazy loading).
You can scroll down a particular element, in that case, target it setting a selector. It could be some specific DIV for example.
If you only want to scroll down the page, you can leave the selector empty.
PRESS A KEYBOARD KEY
You can send a key or some combination of keys (key modifier) to a certain element.
Usually, you will send a text string with the populate-text-field action, but you will send special keys (like Enter) with press-a-keyboard-key action.
Please, note that you need to specify a CSS selector.

SET DROPDOWN VALUE
With this option you can change a dropdown value or iterate on it.
This could work pretty well for e-commerce sites to get all product variations.
There is an option to choose a random value.
That works fine to grab any choice when you need to fill forms and the selected option should vary randomly.

SET CHECKBOX STATE
On this small sandbox, you can see how easy is to change a checkbox state.
You only have to add a Set checkbox state event and target the CSS selector of your desired element.
RTILA can iterate on every element from the Element count select box.

WAIT FOR ELEMENT TO APPEAR
This will allow you to wait until a certain element appears on the screen.
It will work like a semaphore, waiting until the timeout is over.

Variables
Variables are used to store information to be referenced and manipulated in our automation.
Probably you will need to use variables to declare statement Conditions (operands).

Conditions
A Condition is a programming conditional statement that, if proved true, will perform actions or events.
As you see in the image below, a condition is declared between 1 or 2 operands, that should meet the defined statement: Exists, Not Exists, Equals, Not Equals, Contains, Does Not Contain.
The last part is to set what happens when the condition is not met: Do nothing, Break parent loop or Stop automation.
Conditions are commonly used with Loops.

Loops
Loops are needed frequently.
Probably the most common case is with paginations.
On almost all sites that contain a category page with listings, they will use some sort of pagination.
There are many kinds of them, numbered, with a link, with a button, with arrows…
Sometimes you can know in advance how many times you have to loop.
In that case, set the Loop select to For, and define the Start and End limits.
You can set the loop as Infinite and combine it with a Condition.
Don’t be scared about creating an infinite look (or probably you should be scared).
The condition will allow you to create a breakpoint to stop the loop.

This is an example of adding 10 keywords to google and looping the results.

This one is a basic loop searching for the NEXT page button.

A complex project with many categories and listings (click to enlarge).

Here you have a basic pagination schema, really useful (really big image).
