

Flows are chained projects or blocks (single steps) connected that allow us to complete a more complex execution.
In this tutorial, we will create a flow with RTILA, and you will understand how they work.
For this example, I want to execute 3 projects in sequential order:
- scraping categories
- scraping listings and
- craping product details
I will save the results of each project on separate CSV files, and I will merge the results in a final single file at the end of the process, simulating a database JOIN with CSV files.
The first project is returning 50 results and projects 2nd and 3rd return 1.000 results.
One record from the first project will match multiple records from the second project.
A script will combine and merge all the results in a single table at the end of the flow.
PROJECT 1.
Our sample will be targeting the site https://books.toscrape.com/.
The first project will scrape the categories from the sidebar.
Most of the time, categories will not vary too much, then it’s something that we would not scrape again and again, but I’m creating this project for learning purposes.
Here we have a partial view of the sidebar menú:

To grab the links I will create 2 selectors, one for the name and another one for the link.
The project preview should look like this:

All is looking almost perfect, but I want to get the category links with an absolute path.
RTILA allows you to manipulate each FIELD_VALUE.
To prepend some string, we can write:
FIELD_VALUE = "This goes before" + FIELD_VALUE
Create a filter on the category_link selector and prepend the site URL.
It should be an easy task, but you can watch the next video to follow the steps:
Our first project is set. This is what we get executing project 1.

Next, we will program RTILA to grab the book listings.
PROJECT 2.
For the second project, I will grab the product name, the price, and the link to the books.
Usually, the listing pages have pagination. We will learn how a basic loop is built to solve that.
Here you have a quick video with the project 2 setup:
In the project options, I checked to grab the current page URL, here is the screenshot.
From the main RTILA window, go to Projects, select your second project and click Options from the top bar.

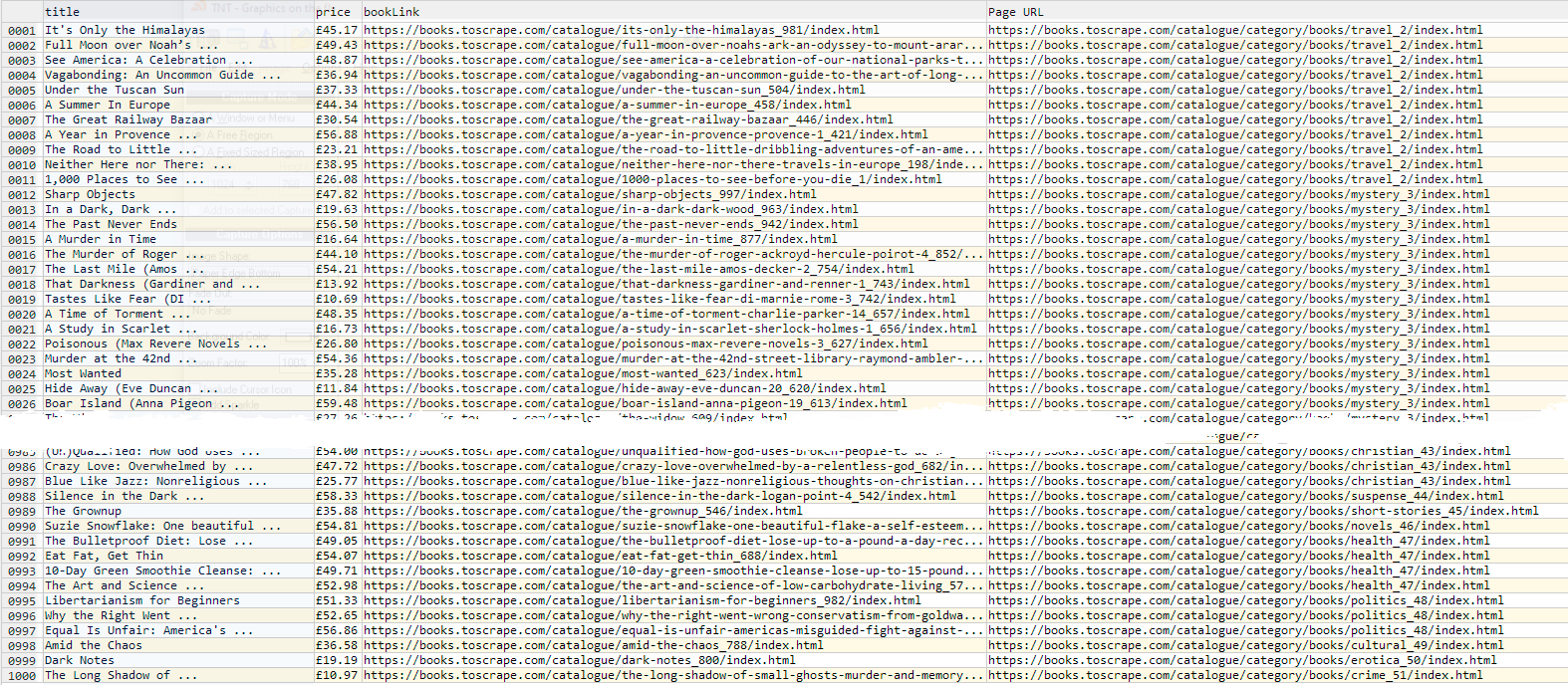
These are the partial results that we will obtain after executing the flow (we haven’t built it yet).
Note that in PROJECT 1 we have a category_link that matches the Page URL column from PROJECT 2.
Ok, let’s summarize what we have done.

PROJECT 3.
Project 3 will scrape the book details page. For my sample, I got the book title, stock and UPC.
Same as PROJECT 2, I included the Page URL on the project options.
The results will look like this.

Probably you noticed that I have selected some values that also appear on the details page.
Usually, the details page will be the proper place to grab as many properties as you can.
For this tutorial, I have simulated that I needed values from each step, maybe you have realized that I have extracted a partial title on Project 2 and the full title on Project 3.
But after this long presentation, I still didn’t show any flow to you.
Remember these RULES:
- Create simple separate projects.
- Each project will contain the URL’s to feed the next project.
- Test the projects separately.
- Chain the projects in a flow.
- Keep as many selectors as you can, for the last project.
Chaining the projects in a flow
Ok, here we go.
A flow can be very complex, I just created a lineal one that will cover all our needs.

We have 3 projects executing one after another. After each execution, the Save to local file block is saving the CSV results to a folder.
I have named the results files as: 1.csv, 2.csv, and 3.csv respectively.
Project 1 is feeding Project 2, and Project 2 will feed Project 3.

This is the Project 2 input view, importing the links from Project 1.

After chaining our 3 projects, we will have the results together in a folder using the Save to local file block.

Bonus content
But, let’s continue the FLOW executing some commands on our computer.
RTILA is running on our machine and we can extend RTILA features with other scripts.
After the 3rd CSV file is saved, add an Execute command block.
Previously I have downloaded XSV, a command-line tool written in RUST that can manipulate CSV files.
I wrote this command in the block:
E:\books\xsv.exe join "category_link" E:\books\1.csv "Page URL" E:\books\2.csv | E:\books\xsv.exe select "!Page URL" -o E:\books\temporal.csv
It looks a bit longer than usual because it’s using absolute paths.
This command will JOIN the files 1.csv and 2.csv and combine them in a temporal.csv file.

That way we preserve the category name from the first project and the price from the second project (remember, this is a project simulation).
The last action in the flow will be to merge the temporal.csv file with the 3.csv file.
E:\books\xsv.exe join "bookLink" E:\books\temporal.csv "Page URL" E:\books\3.csv | E:\books\xsv.exe select "!Page URL,title" -o E:\books\final.csv
In this case, I set the parameters to remove the Page URL (I will keep it on the bookLink column) and the first title (I decided to remove the full title name and remove the short version).
The image below shows the data combined:

And that’s all.
Enjoy a FULLY automated script that allows you to create execution flows.
Summary
A basic flow will contain a couple of projects, or maybe a single project with an action block.
Probably you can create a flow containing a single element if you want to load the URL’s from a file.
Flows are easy to use.
This could be a regular flow, allowing to execute a project with the results of a previous one.

Remember that you need valid URLs to send to the next flow. Create absolute paths.
Some cleanup could be needed, but you don’t need to be Dennis Ritchie to write it.
We saw how to append some text to a string to convert a relative URL to an absolute URL, easy.
This tutorial introduced some desktop tool that was executed from RTILA, you have full freedom to combine this scraper with other programs (macros, automation or command-line tools).
Creating a FLOW allows you to break a complex project into simple steps.
Of course, you can create a project that solves this without flows but probably is harder to achieve.